1. .dbf 확장자 .csv로 변환
- .dbf 파일은 데이터베이스 회사인 디베이스에서 개발한 확장자로 1983년 dBASE II 가 도입되면서 사용되었음
- 때문에 아직도 오래된 소프트 웨어나, 디베이스를 기반으로 하는 소프트웨어는 .dbf 로 파일을 output 하며, 디베이스가 없다면 파일을 읽고 수정하기가 굉장히 번거로움
- 엑셀의 경우도 dbf 파일을 읽을 수 있으나, 자동측정장치와 같은 하드웨어로 대량의 데이터를 장기간 수집했을 경우, 수작업을 통하여 엑셀파일로 접근하는게 어렵기 때문에, 보다 쉽게 .dbf 파일을 .csv 파일로 변환할 수 있어야함
code---------------------------------------------------------------------------------
# 패키지 임포트
import csv
from dbfpy import dbf
import os
import sys
csv_fn = "all.csv"
with open(csv_fn,'wb') as csvfile:
for file_name in os.listdir('.'):
if file_name.lower().endswith('.dbf'):
print ("Converting %s to csv" % file_name)
in_db = dbf.Dbf(file_name)
out_csv = csv.writer(csvfile)
for rec in in_db:
out_csv.writerow(rec.fieldData)
in_db.close()
print ("Done...")
else:
print ("Filename does not end with .dbf")
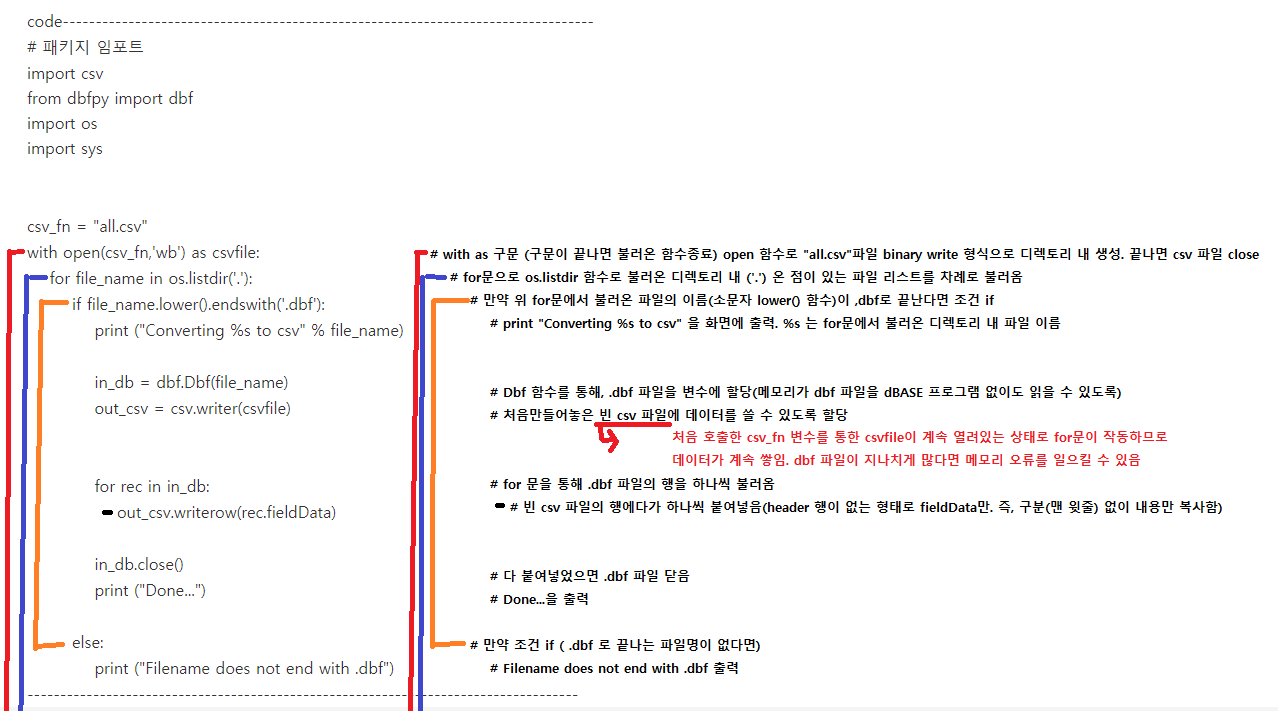
- 위 코드의 구조는 .dbf 파일을 읽은 후, 빈 csv 파일에 내용을 붙여넣어 새롭게 생성하는 구조임
(convert가 아닌 새로운 시트에 복사 생성)
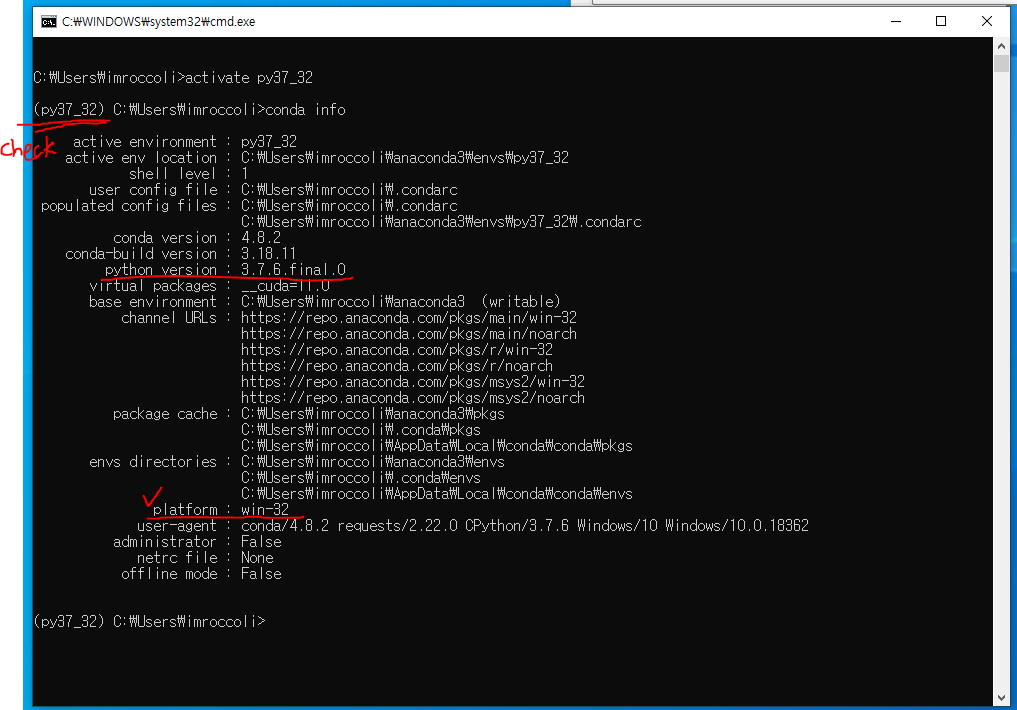
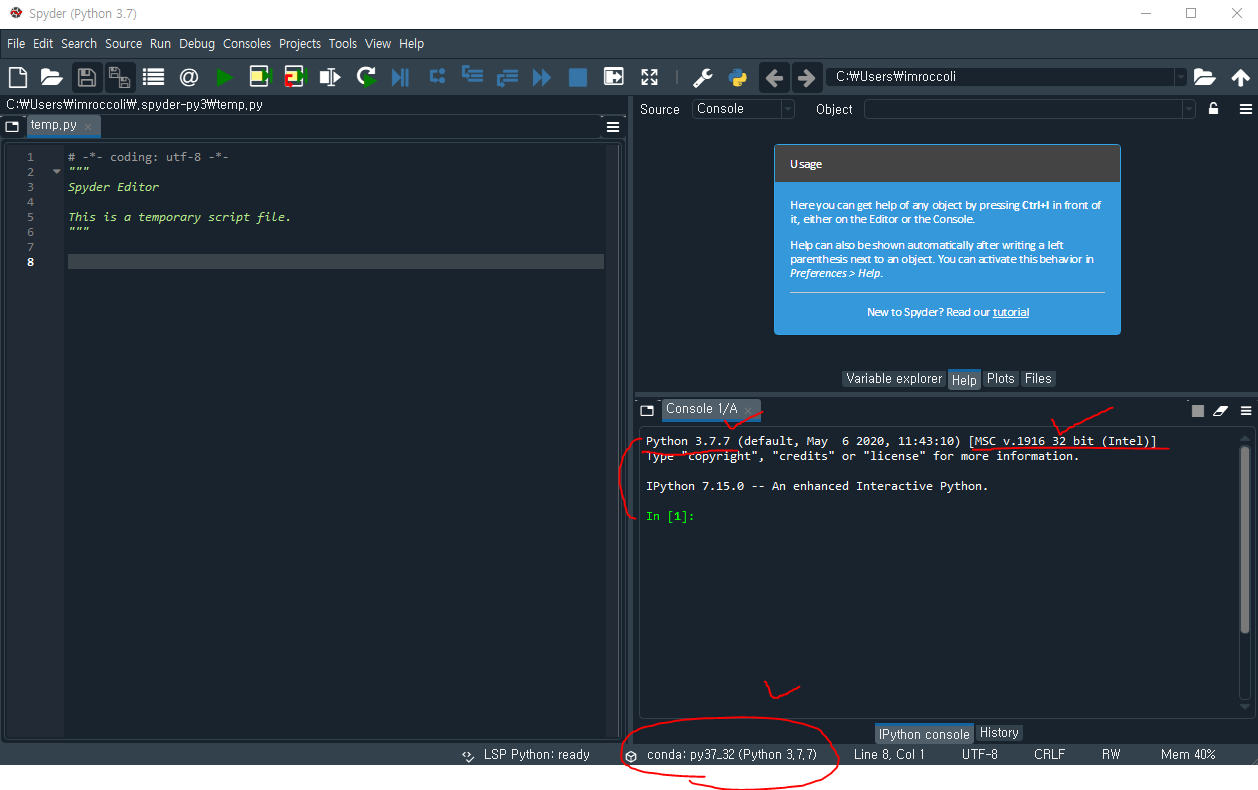
- 패키지 모듈 중 dbf 파일을 읽을 수 있는 패키지 dbf는 파이썬 2.x 버전에서만 사용가능함! 반드시 가상환경 사용
- (아나콘다를 통한 가상환경 명령어 사용 참고 https://imlanktonlifelab.tistory.com/11)
- 변환은 os 모듈의 디렉토리에서 진행되며, 생성 csv 파일 또한 디렉토리 내에 생성됨
- 디렉토리 변경 코드는 아래
code--------------------------------
os.chdir('C:/Projects/dbf2csv/')
-------------------------------------
- 'C:/Projects/dbf2csv/' 대신 디렉토리 붙여넣기
'프로그래밍 > 기타' 카테고리의 다른 글
| [Kaggle practice 캐글 따라하기] #1 Statoil/C-CORE Iceberg Classifier Challenge 중, *.7z 형태 데이터 kernel 상에서 읽기 (0) | 2020.04.22 |
|---|